Experiments that demonstrate the potential of LLM-based solutions for agent delegation.
Table of Contents
- Introduction
- First Step: Synthetic Dataset Creation
- Baseline Approach: Using LLM as a Classifier
- Improving the Baseline: Including User Request Examples
- Additional Findings
- Conclusion
Introduction
As we have shown in our blog post on AI-native organizations, real organizational efficiency gains come not just from using AI agents, but from ensuring the right actors — human or AI agent — are assigned to the right tasks at all times.
With specialization advantages between agents and humans reaching 100x, misallocating tasks imposes massive opportunity costs. Conversely, organizations that master optimal agent allocation unlock exponential productivity gains.
At scale, with thousands of tasks and subtasks, manual delegation breaks down. Automation becomes essential. If an agent can reliably complete a task with high accuracy — and user permissions allow — the agent should be auto-selected and assigned.
Automatic, correct delegation becomes the cornerstone of reliable automation.
A few months ago, we introduced self-service agent creation via natural language instructions on our platform.
As more and more users were onboarded, the agent count grew rapidly, and quickly the fundamental delegation problem (Which agent is most suitable for a particular task?) became increasingly hard to solve automatically.
Hardness of the problem
In an ideal world, the challenge could be framed as a supervised learning task — classifying tasks to the right agents.
In reality, conditions were far more complex due to:
- A wide and growing range of tasks (T)
- A rapidly expanding and potentially unlimited set of user-created agents (A)
- Tasks spanning diverse customer domains (D)
For every task (T), the right agent (A) had to be selected across all domains (D). The complexity of the problem can be expressed as T × A × D — clearly an exponentially hard challenge.
Meanwhile, business needs demanded a solution that was flexible, reliable, and real-time across diverse domains.
Evaluation & Solution Approach
Before testing solutions, we first focused on defining how to evaluate them.
Our evaluation aimed to answer:
- What is the accuracy of agent selection (Top-1 and Top-3)?
- How does accuracy behave as the number of agents scales?
Following Test-Driven Development (TDD) principles, we created evaluation datasets.
Initially, we used synthetic datasets across five core domains:
- Customer support
- Marketing outreach
- Technical documentation
- Sales enablement
- Internal communications
Later, we validated the approach with real customer datasets.
First Step: Synthetic Dataset Creation
Each agent was characterised by:
- Name
- Description
- Instructions
- Tools
To start, we focused on name, description, and sample user requests, creating a synthetic dataset consisting of 70 agents, each assigned five specific tasks. For example:
{
"name": "Acme Corp Outreach Agent",
"description":
"You are a specialized agent tasked with composing professional"
"outreach emails to Acme Corp. Your communications are tailored,"
"engaging, and reflective of our brand’s tone, ensuring alignment"
"with Acme Corp’s business interests.",
"user_request_samples": [
"Draft personalized partnership proposals to Acme Corp",
"Compose follow-up emails after initial outreach to Acme Corp.",
"Tailor outreach messages to align with Acme Corp’s priorities"
]
}
Ground truth datasets were subsequently generated for evaluation purposes:
{
"expected_agent_name": "Acme Corp Outreach Agent",
"user_requests": [
"Draft personalized partnership proposals to Acme Corp",
"Compose follow-up emails after initial outreach to Acme Corp.",
"Tailor outreach messages to align with Acme Corp\u2019s priorities",
"Include specific client details for a personalized touch in Acme Corp communications",
"Clarify service benefits in communications targeted at Acme Corp"
]
}
Now that we had created the evaluation sets, we started testing different solution approaches.
Baseline Approach: Using LLM as a Classifier

As a baseline, we designed a simple LLM-driven classifier, using the following structured prompt:
# Task
You are in charge of accomplishing the following task:
Task:
You MUST select one agent from the list below.
## Agents
Using structured outputs we could then determine the top 3 agents:
from enum import Enum
class Delegates(Enum):
AGENT_ONE = "Agent One"
AGENT_TWO = "Agent Two"
AGENT_THREE = "Agent Three"
AGENT_FOUR = "Agent Four"
AGENT_FIVE = "Agent Five"
class Top3Delegates(BaseModel):
top1: Delegates = Field(
description="The top recommended agent for the task."
)
top2: Delegates = Field(
description="The second recommended agent for the task."
)
top3: Delegates = Field(
description="The third recommended agent for the task."
)
This approach initially produced good results:
| N delegates | Top-1 | Top-3 |
|---|---|---|
| 70 agents | 116/150 (77%) | 143/150 (96%) |
However, when agents were shuffled, performance declined significantly:
| N delegates | Top-1 | Top-3 |
|---|---|---|
| 70 agents (shuffled) | 99/150 (66%) | 132/150 (88%) |
This drop in performance is due to the well-known LLM issue known as “lost in the middle”, where the model struggles to retain context from the middle portions of the prompt.
Learning #1: The order of delegates significantly affects classification accuracy. Using a reranker to present the LLM with only the most relevant agents restores accuracy and improves efficiency by reducing token usage:
| N delegates | Top-1 | Top-3 |
|---|---|---|
| 70 agents (shuffled + rerank) | 114/150 (76%) | 139/150 (93%) |
Improving the Baseline: Including User Request Examples
To improve the baseline approach, the first step was to include user request examples directly in the context of the delegator.
## Agents
{% for delegate in delegates %}
- Name: {{ delegate.name }} Description: {{ delegate.description }}
Examples of possible tasks that this agent can help with:
{% for delegate in delegate.user_request_samples %}
- {{ user_request_sample }}
{% endfor %}
{% endfor %}
| N delegates | Top-1 | Top-3 |
|---|---|---|
| 70 agents (shuffled + rerank + samples) | 122/150 (81%) | 144/150 (96%) |
We then analyzed how the quality of Top-1 matches depends on the number of available agents.
- Accuracy dropped from 89% to 74% as the number of agents increased.
- The decline was gradual, not abrupt, but clearly demonstrated the need for efficient pre-selection of candidates.
This highlighted an important insight:
Scaling agent numbers without smart filtering significantly impacts matching quality.

Despite the open-ended nature of the classification problem, we achieved strong baseline results. For comparison: random chance classification would yield only ~1% accuracy.
Learning #2:
Including user request examples in the delegation context significantly boosts performance.
To further improve results, we identified several potential next steps:
- Query expansion
- Query decomposition
- Model fine-tuning
- Adoption of encoder-based architectures (e.g., ModernBERT)
| N delegates | Top-1 | Top-3 |
|---|---|---|
| 70 agents | 116/150 (77%) | 143/150 (96%) |
| 70 agents (shuffled) | 99/150 (66%) | 132/150 (88%) |
| 70 agents (shuffled + rerank) | 114/150 (76%) | 139/150 (93%) |
| 70 agents (shuffled + rerank + samples) | 122/150 (81%) | 144/150 (96%) |
Additional Findings
During experimentation, we explored methods to measure prediction confidence.
One effective approach: using LogProbs from the model outputs.
To enable this functionality in OpenAI SDK, one can do the following:
response = await async_client.beta.chat.completions.parse(
model=model,
messages=[{"role": "system", "content": rendered_template}],
response_format=Top3Delegates,
temperature=0,
top_p=1,
frequency_penalty=0,
presence_penalty=0
logprobs=True,
top_logprobs=5,
)
LogProbs offer a probability distribution over choices, helping determine when a model is certain versus when it’s uncertain.
Examples from our experiments:
- High Certainty:
- Compliance Review Agent selected with 99.86% confidence — clear, reliable match.
- Low Certainty:
- Invoice & Billing Agent selected with 42.56%, closely followed by Legal Research Agent at 37.56% — indicating uncertainty and suggesting the need for additional validation or richer context.

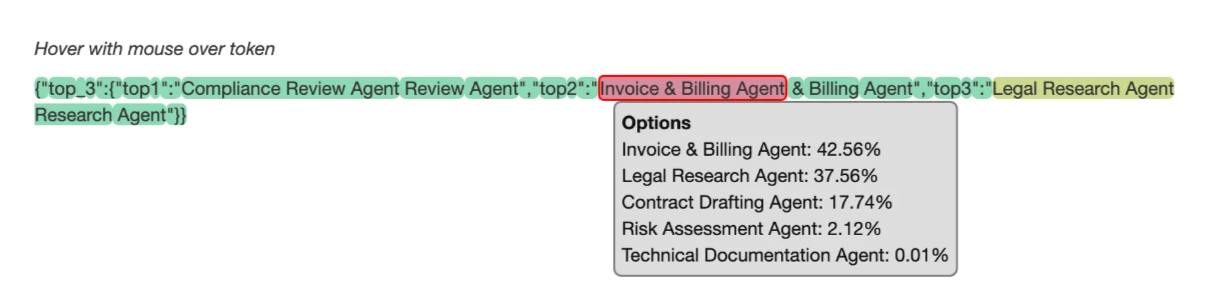

The insights gained from LogProbs helped refine when manual review might be necessary — particularly when probability scores between agents were close.
Learning #3:
Using LogProbs provides valuable certainty signals.
Enabling log probabilities in model responses improves evaluation of model confidence.
Learning #4:
Implementing a rubric-based confidence scoring system further enhanced clarity and interpretability, offering a more structured way to assess prediction quality:
class Confidence(BaseModel):
reasoning: str = Field(
description="A concise explanation detailing how the agent arrived at the confidence score.",
)
rubric: Literal[1, 2, 3, 4, 5] = Field(
description="""
### Rubric (1 to 5)
- **1: Very Low Confidence**
<your explanation>
- **2: Low Confidence**
<your explanation>
- **3: Medium Confidence**
<your explanation>
- **4: High Confidence**
<your explanation>
- **5: Very High Confidence**
<your explanation>
""",
)
Conclusion
Our experiments confirmed the strong potential of LLM-based solutions for agent delegation.
Key practical techniques included:
- Reranking candidate agents
- Including user request examples
- Leveraging model probability outputs for evaluation and decision-making
While this solution already significantly improves the user experience on the Interloom platform, its impact reaches beyond that.
In multi-agent systems, an orchestration agent must reliably allocate and coordinate tasks across multiple agents.
Reliability at this stage is critical — it directly determines the overall quality and efficiency of the system and is key to operationalize the AI agent advantages.
We have successfully deployed a similar solution in production, proving it to be:
- Highly scalable
- Adaptable across diverse domains
- Robust and effective as a foundation for future innovations.